
继DeepSeek掀翻山地风云之后亚博体育(中国)官方网站,AI圈这两天再次被“战栗”。
近日有媒体报说念称,李飞飞等斯坦福大学和华盛顿大学的征询东说念主员以不到50好意思元的云有筹商用度,顺利检会出了一个名为s1的东说念主工智能推理模子。
该模子在数学和编码才智测试中的融会,据称与OpenAI的O1和DeepSeek的R1等顶端推理模子不相高下。
50好意思元复刻一个DeepSeek,这几乎是逆了三十三重天。
不外,也有不雅点指出,s1是通过蒸馏法由谷歌的Gemini2.0 Flash Thinking Experimental索要出的。
那么事实到底是若何的?s1模子的旨趣是什么?若何得出50好意思元本钱的?
s1模子站在巨东说念主肩膀上
三言搜检了s1论文,发现这可能又是被“战栗体”们给夸大了。

论文摘抄中写说念:测试时期缩放是一种很有长进的讲话建模新方法,它哄骗格外的测试时有筹商资源来提高性能。
最近,OpenAI的o1模子展示了这种才智,但未公开其方法,激发了许多复现尝试。咱们寻务好意思满测试时期缩放和苍劲推感性能的最浮浅方法。
领先,咱们尽心整理了一个包含1000个问题的少许据集s1K,这些问题都配有推理经由,筛选时依据三个经过消融现实考证的行径:难度、各种性和质地。
其次,咱们开拓了 “预算强制” 方法,通过在模子尝试拆伙时强制拒绝其想考经由,或屡次向模子的生成内容中追加 “恭候” 来延迟想考时期,从而限度测试时的有筹商量。
这能让模子对谜底进行二次查验,络续能修正舛误的推理法子。在使用s1K对Qwen2.5-32B-Instruct讲话模子进行有监督微调,并为其配备 “预算强制” 功能后,咱们的模子s1-32B在竞赛数学问题(MATH 和 AIME24)上的融会比o1-preview跳跃27%。
此外,对s1-32B使用 “预算强制” 方法进行推广,能够在无测试时插手的情况下提高性能:在AIME24上的准确率从50%提高到57%。
在论文的摘抄中,仍是说明了是使用s1K对Qwen2.5-32B-Instruct讲话模子(阿里云通义千问)进行有监督微调,并为其配备 “预算强制” 功能。
也即是说s1模子的检会并非从零运转,而是设立在已具备苍劲才智的开源基础模子之上。
小引中写说念:尽管有大宗对o1模子的复现尝试,但莫得一个公开显明地复现出测试时缩放行径。因此,咱们提议疑问:好意思满测试时缩放和苍劲推感性能的最浮浅方法是什么?
咱们展示了,仅使用1000个样本进行下一个标志展望检会,并通过一种浮浅的测试时工夫 “预算强制” 来限度想考时长,就能得到一个苍劲的推理模子,其性能会跟着测试时有筹商量的加多而提高。
具体来说,咱们构建了s1K数据集,它由1000个经过尽心筛选的问题构成,这些问题都配有从Gemini Thinking Experimental(Google,2024)索要出的推理经由和谜底。咱们在这个少许据集上对一个现成的预检会模子进行有监督微调(SFT),在16个H100 GPU上仅需检会26分钟。检会完成后,咱们使用 “预算强制” 方法来限度模子在测试时破钞的有筹商量。
这部分又提到,s1K数据集的1000个问题都配有从Gemini Thinking Experimental索要出的推理经由和谜底。并在s1K这个少许据集上对一个现成的预检会模子进行有监督微调。
这也再次说明,s1模子是借助了其他苍劲模子的才智。
现实方法:数据集筹办、预算强制、测试时期推广方法
从整篇论文来看,其主要的现实方法包括数据集筹办、预算强制,以及测试时期推广方法。
领先是筹办一个包含1000个问题的微型数据集s1K。
该团队基于质地、难度和各种性三个行径,从16个开首蚁集59029个问题,经API舛误筛选、时局问题过滤等,最终细则1000个高质地样本,涵盖数学、科学等50个不同领域。
其次是预算强制。
预算强制旨趣是通过限度测试时的有筹商量(如想考标志数)来优化模子性能。
具体方法是在模子生成经由中,强制拆伙想考经由或延迟想考时期,促使模子再行查验谜底,修正舛误推理法子。
再即是测试时期推广方法,分为次序推广和并行推广。
次序推广是基于模子的中间拆伙渐渐优化推理经由。
而并行推广是通过屡次寥寂生成贬责决策并采用最好拆伙来提高性能。
现实中的具体检会,是使用s1K对Qwen2.5-32B-Instruct进行有监督微调,16个H100 GPU上检会26分钟。
然后接管AIME24、MATH500和GPQA Diamond三个推理基准测试,将s1-32B 与多种模子对比。
终末得出论断,仅在1000个样本上进行监督微调并聚首预算强制工夫,即可构建出具有苍劲推理才智和测试时推广才智的模子。
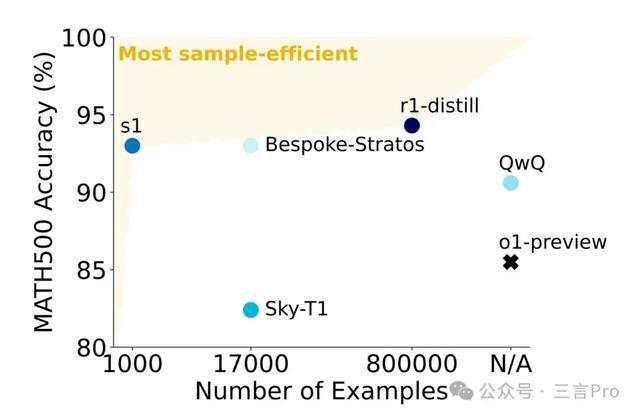
由此可见,s1模子确切有不俗的融会,但它是站在了巨东说念主肩膀上的。
“不到50好意思元”仅为云有筹商功绩用度
在通篇论文中,并未提到过50好意思元的本钱。
而论文中有一句“检会在16个NVIDIA H100 GPU上只需26分钟”,这梗概即是“50好意思元本钱”的由来。
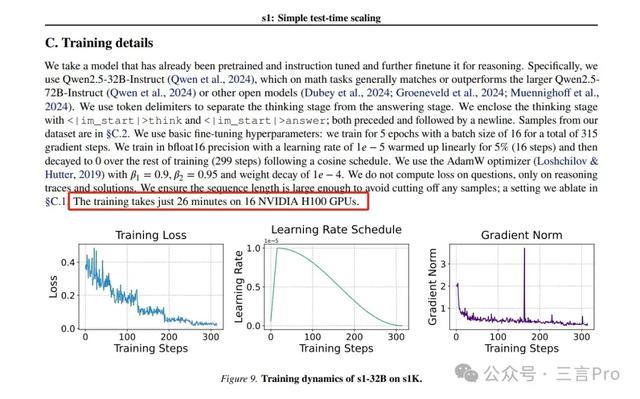
据财联社报说念,“不到50好意思元”仅为云有筹商功绩用度,不包括功绩器、显卡等硬件参预用度,因这部分仍是由云厂商承担。
DeepSeek若何看?
“50好意思元复刻DeepSeek”这样的标题亚博体育(中国)官方网站属实颤动,DeepSeek会如何看待这事呢?
笔者就此事向DeepSeek提了两个问题。
问题一:近日有媒体报说念称,斯坦福李飞飞团队以不到50好意思元的本钱检会出与OpenAI的O1,以及DeepSeek的R1等顶端推理模子不相高下s1模子,分析一下为什么会本钱这样低?
斯坦福李飞飞团队以极低本钱检会出与OpenAI、DeepSeek等顶尖模子性能接近的S1模子,这一蹂躏可能由以下工夫和管理成分驱动:
模子架构创新
参数高效蓄意:接管稀疏激活架构(如MoE)或动态有筹商机制(如自相宜深度/宽度),在保捏性能的同期减少有筹商量。
注视力机制优化:使用FlashAttention、分组查询注视力(GQA)等工夫,裁减内存占用和有筹商复杂度。
常识蒸馏:通过大模子疏导小模子检会(如logit蒸馏、中间层特征对皆),提高小模子性能。
2.检会计谋蹂躏
数据高效哄骗:
基于主动学习的中枢样本筛选(如使用不细则性采样)
合成数据生成(LLM生成高质地检会样本)
数据增强的造反检会(如Diffusion模子生成变体)
优化算法校正:
二阶优化器(如Sophia)好意思满更快的经管速率
动态批处理(凭据梯度方差调整batch size)
课程学习与渐进式检会计谋
羼杂精度3.0:聚首FP8/FP16羼杂精度与梯度量化,内存效能提高4-8倍。
3.硬件哄骗革命
异构有筹商架构:
使用TPU/GPU混书册群,优化任务分拨
哄骗消费级显卡(如RTX4090)的稀疏有筹商才智
弹性检会系统:
基于Kubernetes的动态资源治疗
霸占式实例的容错检会(Checkpointing频率优化)
模子切片工夫:通过ZeRO-Infinity好意思满超大畛域模子参数卸载,单卡可检会参数目提高10倍。
此外,DeepSeek还列举了软件栈深度优化、表面蹂躏支柱、本钱限度计谋等原因。
潜在挑战与截止
这一蹂躏标志着AI研发正在从"暴力有筹商"向"智能有筹商"转型,将来可能出现更多基于算法创新的低本钱模子。不外本色产业落地仍需计议推理本钱、部署复杂度等概括成分,建议捏续重视后续工夫细节浮现和第三方复现拆伙。
问题二:你若何看通过蒸馏监督微调进行模子检会?
不外,在问这一问题的时候DeepSeek出现了“宕机”阵势,笔者屡次尝试发问,而得到的回报一直是“功绩器忙绿,请稍后再试。”
于是笔者通过纳米AI搜索App使用DeepSeek-R1-360高速专线发问这一问题。
DeepSeek回报称,通过蒸馏(Distillation)进行监督微调(Supervised Fine-tuning)是一种有用的模子检会方法,尤其在模子压缩、迁徙学习和提高模子性能方面具有显耀上风。
DeepSeek还从工夫布景与中枢宗旨、上风与适用场景、潜在挑战与贬责决策、典型应用领域、将来发展主见等多个角度,对蒸馏以及监督微调进行了详备分析。
终末,DeepSeek还作出了以下记忆:
通过蒸馏进行监督微调是一种高效且天果然模子检会方法,能够在模子压缩、迁徙学习和性能优化等多个方面带来显耀收益。尽管该方法濒临一些挑战,但跟着工夫的束缚发展和创新,其应用长进将愈加庞大。在本色应用中,需要凭据具体任务需乞降工夫条目,合理蓄意蒸馏计谋,并衡量有筹商本钱与性能提高之间的磋议。
该如何看待蒸馏监督微调?
对于s1模子本钱低的原因,DeepSeek的分析中也提到了蒸馏。DeepSeek还详备的分析了蒸馏的上风和存在的挑战。
蒸馏和监督微调的聚首,DeepSeek也赐与敬佩。
事实上,好多主流大模子也都用过数据蒸馏的方法。比如,DeepSeek-R1模子使用了强化学习和大畛域数据蒸馏,Kimi k1.5也使用了强化学习和大畛域数据蒸馏。
这也说明,蒸馏在模子检会中是一种频频被用到的花式。
据报说念,阿里云阐述,李飞飞团队以阿里通义千问Qwen2.5-32B-Instruct开源模子为底座,在16块H100GPU上监督微调26分钟,检会出新模子s1-32B,获得了与OpenAI的o1和DeepSeek的R1等顶端推理模子数学及编码才智稀少的后果,以至在竞赛数学问题上的融会比o1-preview跳跃27%。
s1模子这一案例,梗概会给将来的征询提供一定的主见。
不外,蒸馏毕竟是设立在苍劲开源模子的基础之上,并非小模子的自己才智。
“50好意思元复刻DeepSeek”这样的标题,属实有些“战栗体”了。